

Lab Note · Paper Explainer · Part II
Toward Efficient Data-Centric Training, Part II: Beyond What to Select - How Much Data Should We Use?
Part I asked whether models can learn what data they need. PODS asks the complementary question: even with a good selector, should the model see the same amount of data throughout training?
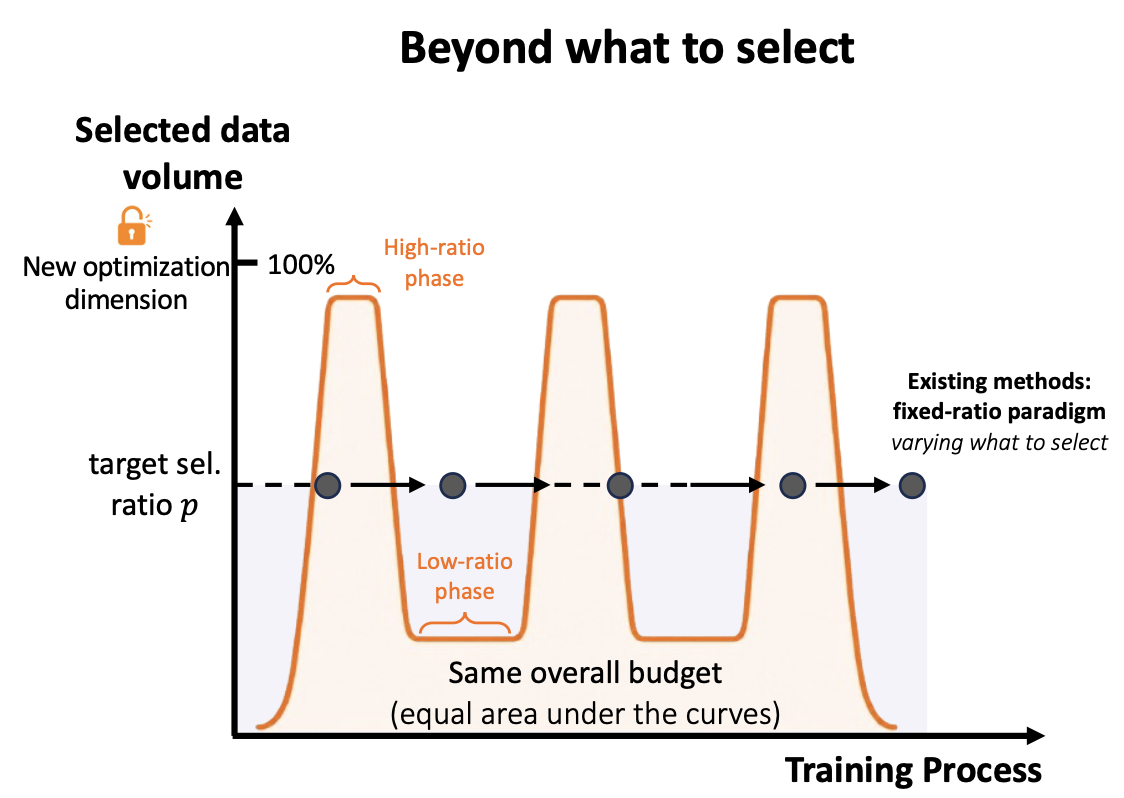
Why Fixed-Ratio Selection Is Limited
Most data selection methods focus on deciding what to select. They may dynamically change the identity of selected samples, but the selected data volume is usually fixed by a target ratio such as 50% or 70% throughout training.
That assumption is convenient, but training is not static. Early, middle, and late training phases can have different optimization needs. Sometimes, seeing less data can act like regularization by forcing the model to focus on informative or harder samples. At other times, seeing more data is important for coverage and stable optimization.
If the ratio is too low, training may be efficient but unstable or biased. If the ratio is too high, training is more stable but loses much of the efficiency and regularization benefit. PODS treats the selected data volume as a temporal control signal rather than a fixed cost knob.
The Core Idea
PODS stands for Plug-and-play Oscillatory Data-volume Scheduling. Its core idea is simple: alternate between low-ratio phases and high-ratio phases during training.
Low-ratio phases expose the model to a smaller amount of selected data. These phases strengthen the regularization effect induced by data selection and reduce computation. High-ratio phases expose the model to more data, improving coverage and helping optimization recover.
The important constraint is that PODS works under the same cumulative data budget as the fixed-ratio baseline. The total amount of data used across training does not exceed the target budget. What changes is when the data is used.
Low-ratio phase -> High-ratio recovery phase -> Low-ratio phase -> High-ratio recovery phase
Why Oscillation Helps
The intuition comes from viewing data selection through optimization. When training on selected data, the stochastic gradient differs from the full-data gradient. This difference can introduce an implicit regularization effect, and PODS shows that the strength of this effect is modulated by the instantaneous selection ratio.

A lower selection ratio leads to stronger selection-induced regularization, which can reduce overfitting and improve generalization. But if the ratio remains too low for too long, the model may lose data coverage and optimization can become unstable.
A higher selection ratio weakens this regularization effect, but improves coverage and makes optimization closer to full-data training. PODS is designed to exploit both sides of this trade-off rather than choosing one fixed point.
PODS Is Not Another Scoring Rule
PODS does not propose a new sample-importance metric. It is orthogonal to selectors based on loss, uncertainty, gradient norm, clustering, coverage, or learned data policies such as Data Agent.
A selector decides what to select. PODS decides how much to select at a given training stage. This makes it a lightweight module that can be placed on top of existing static or dynamic data selection methods.
What The Experiments Show
PODS is evaluated across image classification, fine-grained recognition, long-tailed classification, out-of-distribution generalization, object detection, and LLM instruction tuning.
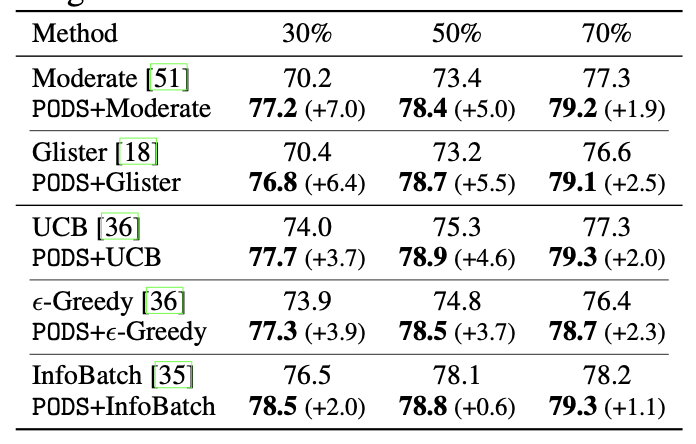
On ImageNet-1k, PODS reduces training cost while maintaining or improving accuracy, showing that data-volume scheduling can scale beyond small benchmarks. The paper reports 50% ImageNet-1k training-cost reduction with improved accuracy.
PODS also generalizes to more challenging recognition settings. On fine-grained classification, it preserves or improves full-data performance with reduced training costs. On long-tailed recognition, it improves results especially for medium-shot and few-shot categories, suggesting that scheduled data exposure can help models learn more balanced representations.
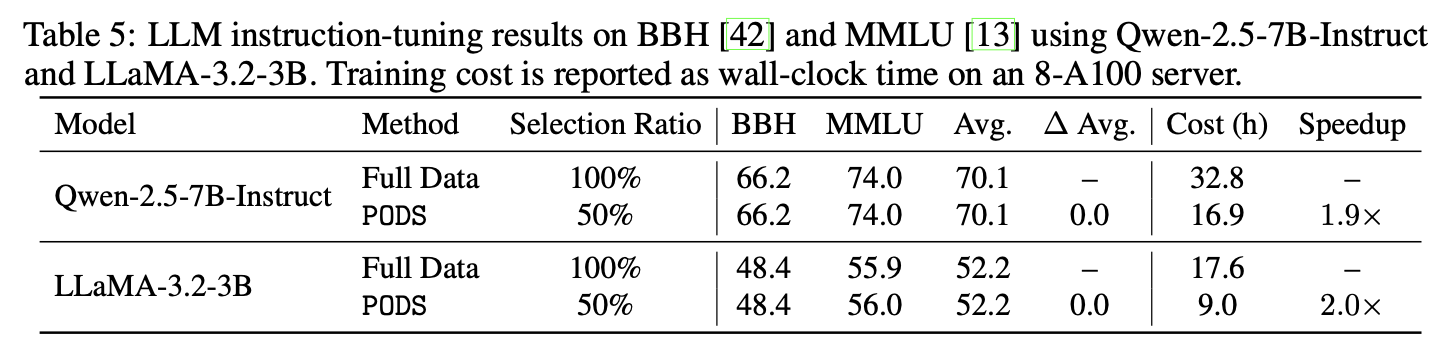
In large-scale fine-tuning experiments with Qwen and LLaMA models, PODS accelerates instruction tuning while maintaining competitive performance on benchmarks such as MMLU and BBH. This suggests that scheduling data volume is useful for both vision and language model training.
Why This Matters
Together, Data Agent and PODS form a more complete picture of efficient data-centric training.
Part I: learn what data to select.
Part II: schedule how much data to use.
Both works point in the same direction: data should not be treated as a static object outside the training loop. It can become an adaptive component of model optimization, shaping efficiency, regularization, and generalization.