

Lab Note · Paper Explainer · Part I
Toward Efficient Data-Centric Training, Part I: Can Models Learn What Data They Need?
Modern AI training is increasingly expensive, but not every training example is equally useful at every stage. Data Agent asks whether a model can learn which data it needs while training is still unfolding.
Why Data Selection Needs To Be Adaptive
Data selection is often treated as a cost-reduction tool: use fewer samples, train faster, and preserve performance if possible. That view is useful, but incomplete. The usefulness of a sample is not fixed.
Early in training, a model may need examples that help build broad representations. Later, it may need samples near the decision boundary, uncertain samples, or cases that reveal what the model still misunderstands. A sample that is useful at one stage can become redundant at another.
Many existing methods rely on predefined scoring rules such as loss, gradient norm, clustering distance, or other handcrafted metrics. These rules can be effective in specific settings, but they are often static, snapshot-based, or tied to a particular task. Data Agent reframes the problem: data selection should be an adaptive part of optimization, not only a preprocessing step.
The Core Idea
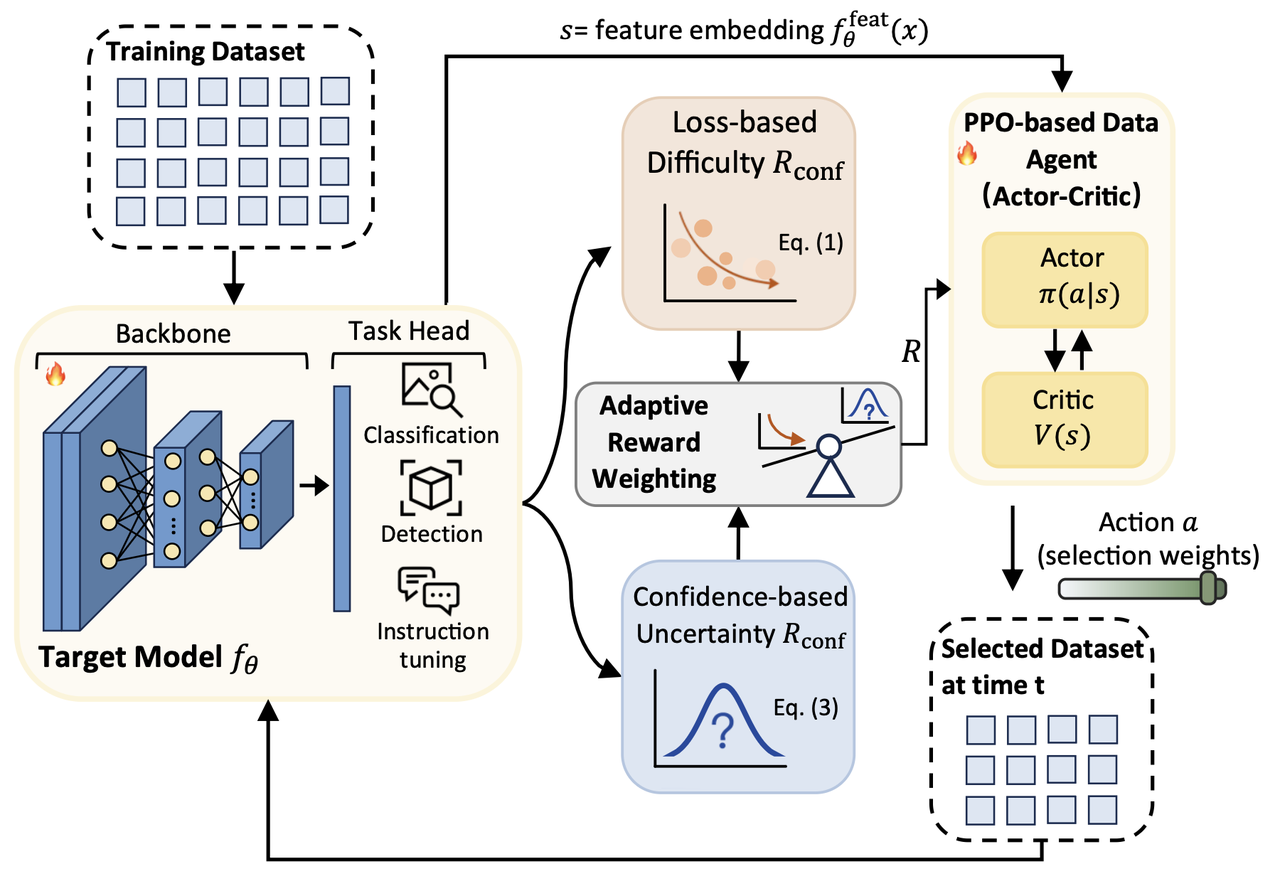
Data Agent places a lightweight agent inside the training loop. At each stage, the agent observes the current state of the target model and outputs sample-wise selection weights. The selected data is then used to update the model. After the update, the model’s new state becomes fresh feedback for the agent.
This creates a closed loop:
Model state -> Data Agent -> Selected data -> Model update -> New model state
Instead of manually designing one static importance score, Data Agent learns a data policy that co-evolves with the model. The target model changes because it trains on selected samples, and the agent changes because it receives training-aware feedback from the evolving model.
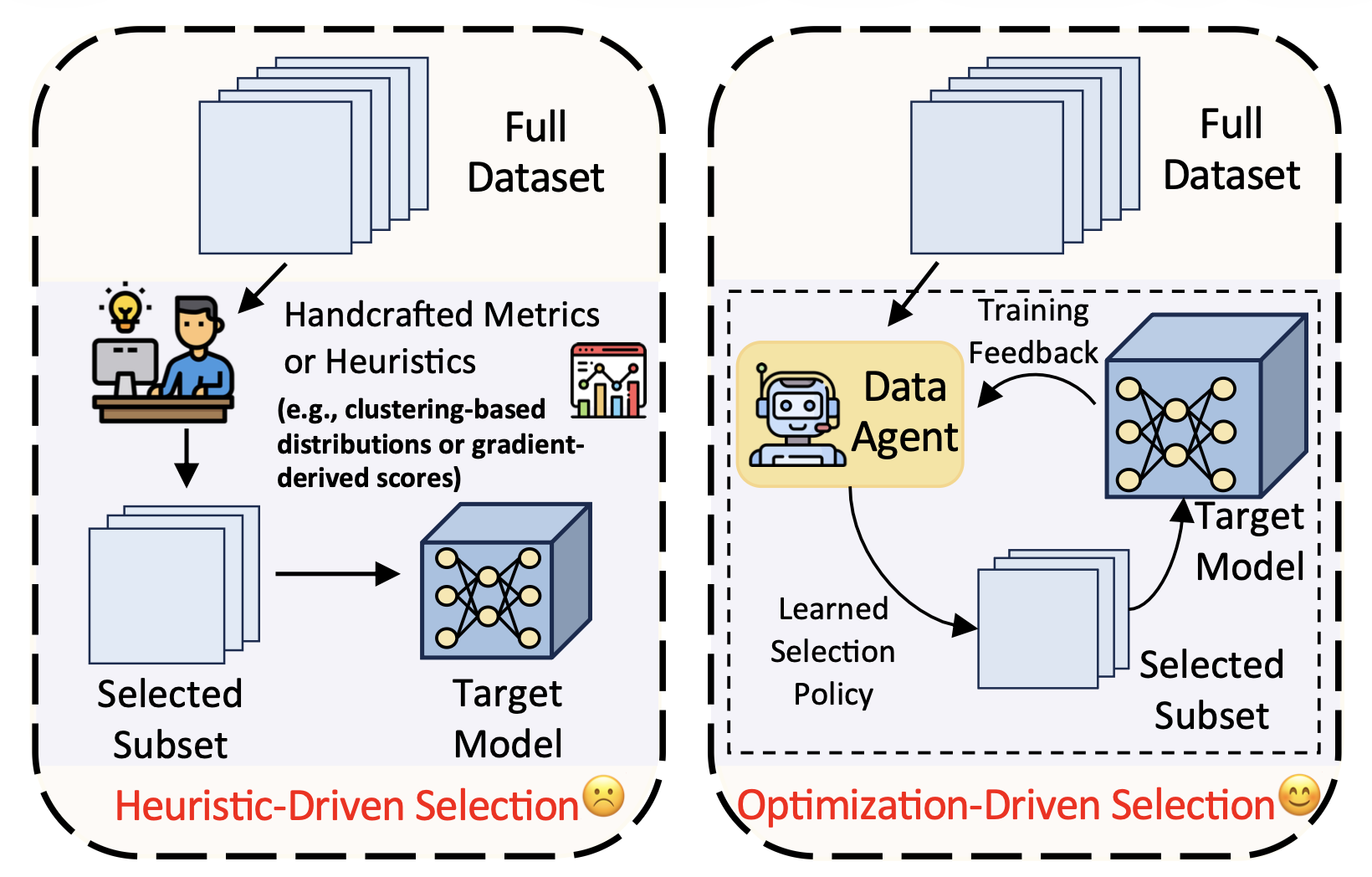
More concretely, Data Agent formulates dynamic data selection as a sequential decision-making problem. The agent observes feature representations from the target model as its state, outputs continuous selection weights as actions, and prioritizes samples with higher weights during training.
What Guides The Agent?
A central question is how the agent knows which samples are useful. Data Agent uses two complementary training-aware signals.
Difficulty captures what the model has not learned well. It is based on sample loss: high-loss samples often expose under-learned regions of the data distribution and can have larger optimization impact.
Uncertainty captures where the model is unsure. A sample may be classified correctly but still lie near a decision boundary. Predictive entropy helps identify these samples and encourages the agent to refine regions where confidence remains low.
The relative importance of difficulty and uncertainty changes over training. Data Agent therefore introduces an adaptive weighting mechanism that balances the two signals automatically, rather than relying on a fixed manually tuned reward weight.
What The Experiments Show
Data Agent is evaluated across image classification, advanced vision architectures, object detection, semantic segmentation, LLM instruction tuning, and noisy-data settings. This breadth matters because the framework is meant to be dataset-agnostic and task-agnostic rather than a metric designed for one benchmark.
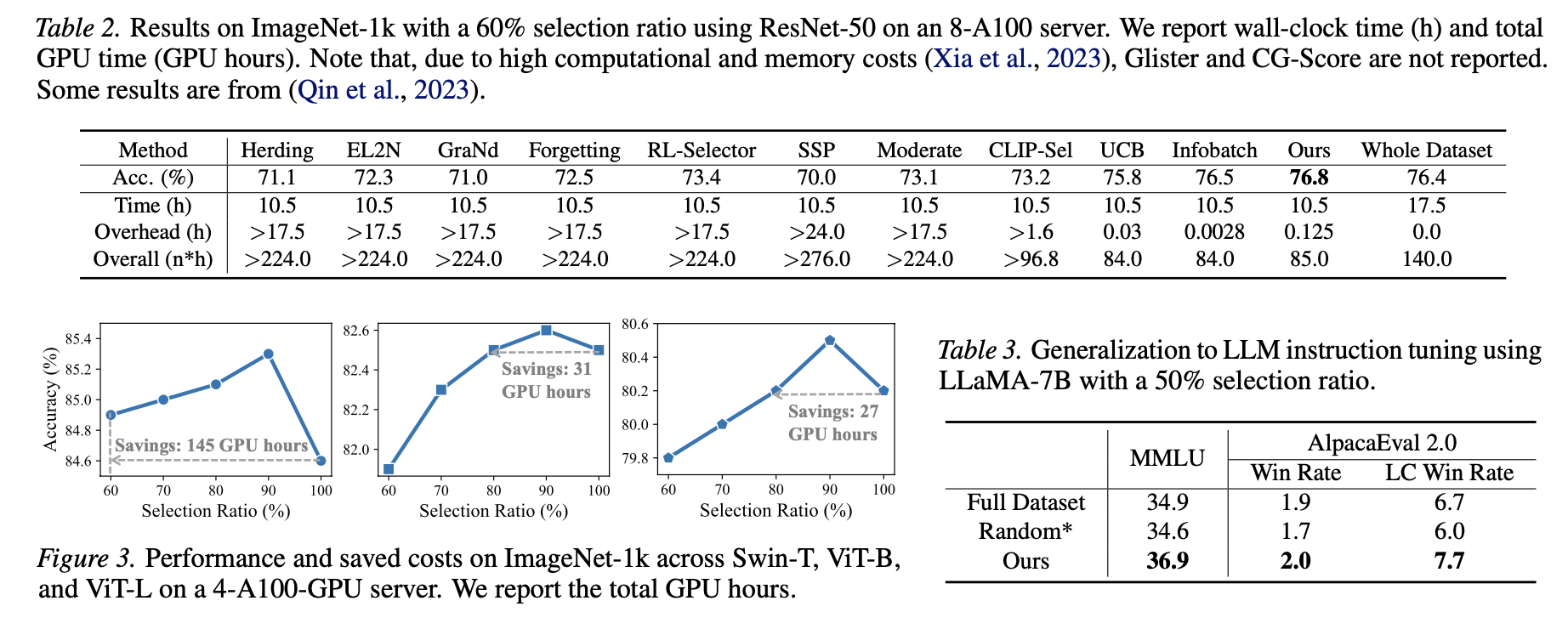
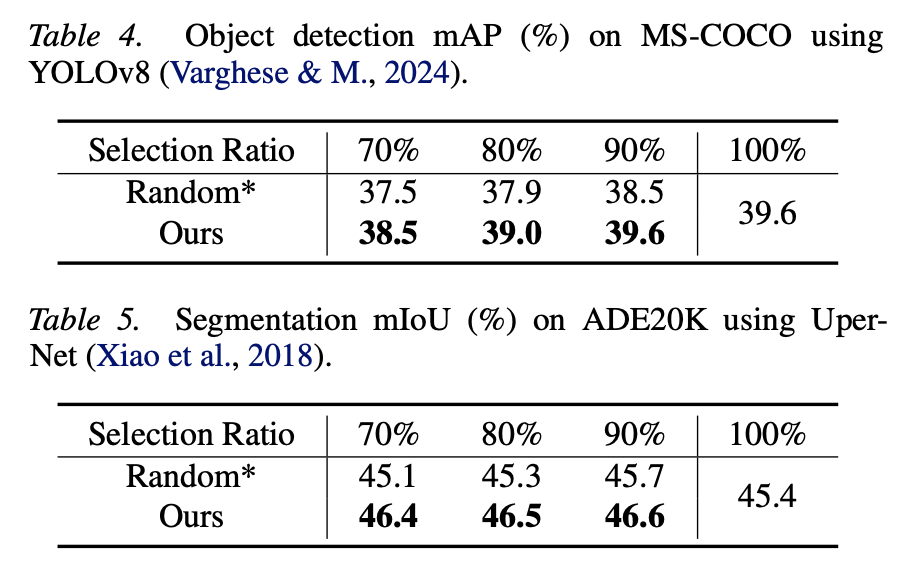
On ImageNet-1k, the paper reports substantial training-cost reduction while maintaining or improving accuracy. The method also remains effective across ResNet, ViT, and Swin Transformer backbones. Beyond classification, Data Agent extends to MS-COCO object detection with YOLOv8 and ADE20K semantic segmentation with UperNet.
The framework also applies to LLM instruction tuning. With only part of the training data, Data Agent improves performance on benchmarks such as MMLU and AlpacaEval compared with full-data training, suggesting that adaptive data selection is useful beyond vision models.
Why This Matters
Data-centric AI often treats data as something fixed: collect it, clean it, filter it, and then train. Data Agent points to a more interactive view. The model can learn from the data distribution, receive feedback, and decide which samples are most useful at different stages of optimization.
This changes data selection from a static preprocessing decision into a learned training policy. It also motivates a second question: even if we know which samples to select, should the model always see the same amount of data throughout training?
That question leads to Part II: scheduling how much data the model should use over time.