Research
At the DeCLaRe Lab, we engage ourselves in multiple research topics with the aim to improve semantic understanding of media and to build simple yet intuitive algorithms. We are always on the lookout to explore interesting directions and our motto is to generate impactful research.
Our current research interests can be broadly categorized as:
Multimodal Interaction
: Adobe Research.
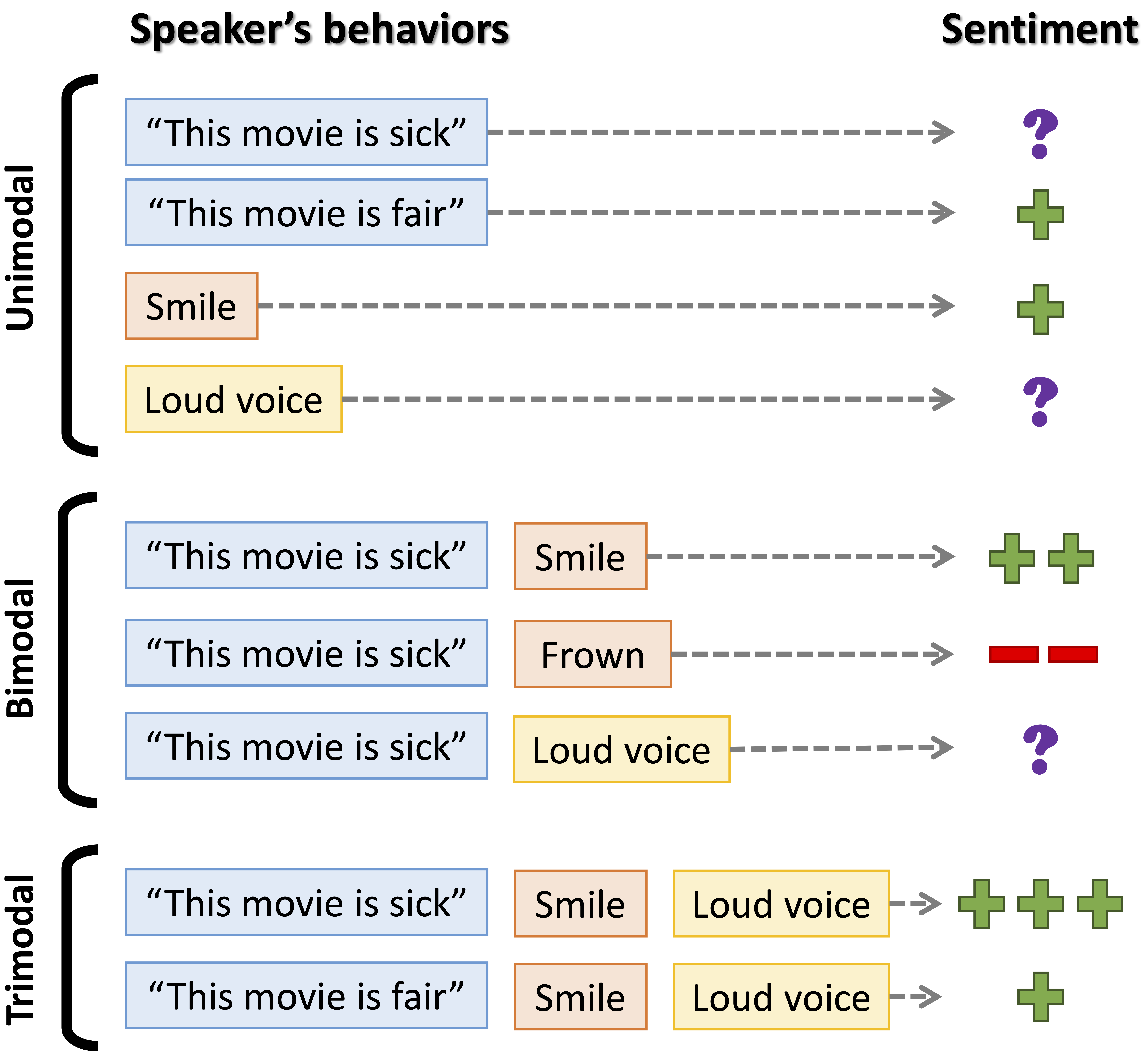
Multimodal Sentiment Analysis: Traditional sentiment analysis has been primarily applied to a wide variety of texts. In contrast, sentiment analysis on user-generated content is fundamentally multimodal in nature and has gained attention due to the explosive growth of many social media platforms. The primary advantage of multimodal treatment is the surplus of behavioral cues present in acoustic and visual modalities, which provides important information to better identify affective states of the opinion holder. This allows to create a more robust sentiment analysis model.
In this topic, we are interested in finding effective fusion strategies of multimodal data along with building robust sentiment analysis systems that can be deployed in the wild.
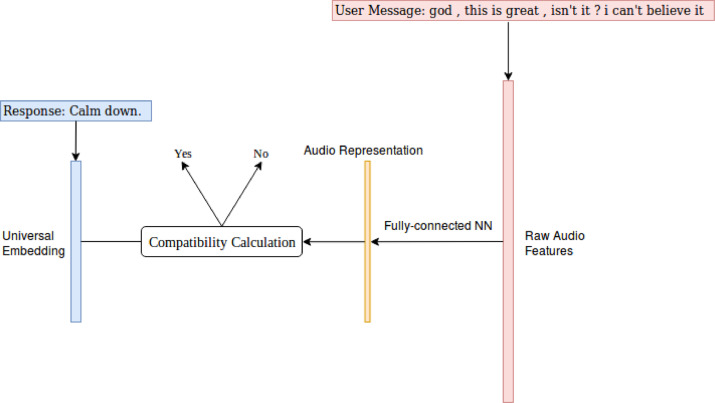
Multimodal Dialogue Processing: Research on building dialogue systems that converse with humans naturally has recently attracted a lot of attention. Most work on this area assumes text-based conversation, where the user message is modeled as a sequence of words in a vocabulary. Real-world human conversation, in contrast, involves other modalities, such as voice, facial expression and body language, which can influence the conversation significantly in certain scenarios. In this project, we are exploring the impact of incorporating the audio features of the user message into generative dialogue systems.

Multimodal Sarcasm: Sarcasm is a linguistic device that uses irony to express contempt or ridicule. Despite being a linguistic problem, sarcasm often lacks explicit linguistic markers, thus requiring additional cues that can reveal the speaker’s intentions. Our work in this area is to leverage multiple modalities and/or context history in dialogues to detect contextual incongruity that goes beyond the surface text. Read more about our efforts in this topic.
Commonsense-aware NLP
: The MoE Tier-2.
Commonsense knowledge (CSK) involves the basic understanding of situations and events commonly shared amongst people, which affects our logical and social decisions in day-to-day life. The quest for AI to mimic such behavior – to understand both human needs, actions, and to interact with us – makes it imperative for them to incorporate CSK. For example, in the sentence, Can an elephant enter the doorway?, CSK is required to compare the size of the two objects. Such information about the sizes of elephant and door can be acquired via online articles (e.g. Wikipedia), without any need to visibly observe them. This kind of inference, though simple for humans, becomes extremely different for machines as such knowledge might not be present in explicit form both in the current sample and also in historical training data. Thus, equipping deep neural models with such CSK is paramount to their understanding and reasoning capabilities, albeit challenging. Our primary goal is to leverage CSK to improve the performance of a wide range of NLP problems, thus showing the worthiness of CSK for NLP at large. The problems we will consider include, but are not limited to, natural language inference, domain adaptation, dialogue generation, and zero-shot learning.
Question Answering
: DSO National Laboratories, AME Programmatic Fund.
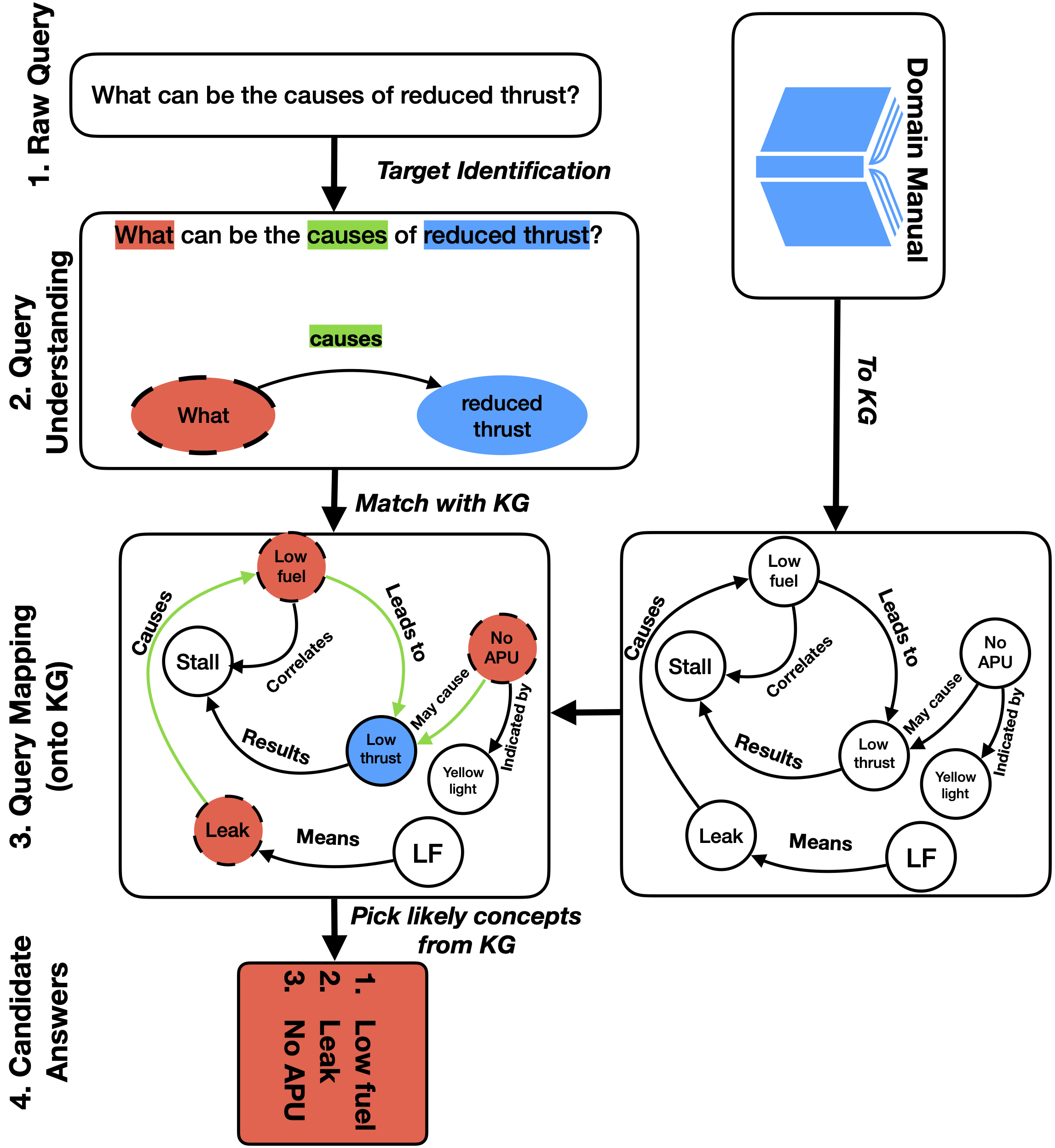
Integrating reasoning for question answering (QA) with explanation is a critical problem in the progress of natural language understanding. The recent works in QA (BiDAF, GA Reader, AoA Reader, etc.) on challenge machine compresenhion datasets (SQuAD, RACE, Narrative QA, etc.) have focused on ‘shallow’ QA tasks that can be tackled by existing retrieval-based techniques or learning surface patterns. With the progress of ‘attention’ mechanisms, these models have become very good in lexical matching to answer questinos. However, it is unclear whether they posses ability to understand the complex semantics required for the task.
To address this problem, recent datasets (CommonsenseQA, SQuAD 2.0, HotpotQA, MutiRC, etc.) pose ‘complex’ questions requiring intelligent reasoning and inference capabilities from the agent. Although, the reasoning required to tackle these QA tasks has many forms, it is often studied in a very narrow sense. Ideally, answering these “complex” questions should require inference/reasoning over multiple spans, including causal, abductive, deductive, inductive, temporal, quantitative and many other kinds of reasoning. Moreover, there has been growing interest for explainability of QA algorithms, along with many other AI challenges at large. Here, the goal is to provide understandability over the reasoning adopted by the models to decide a particular solution. Thus, instead of just answering a specific query, the system should be able to provide explanations for the judgement it made, and be able to provide further recommendations in an interactive manner. To combat these challenges, we are exploring ways to make QA systems perform causal reasoning, leverage external knowledge and generate explanations.
Affective and Empathetic Dialogue Understanding
: Adobe Research.
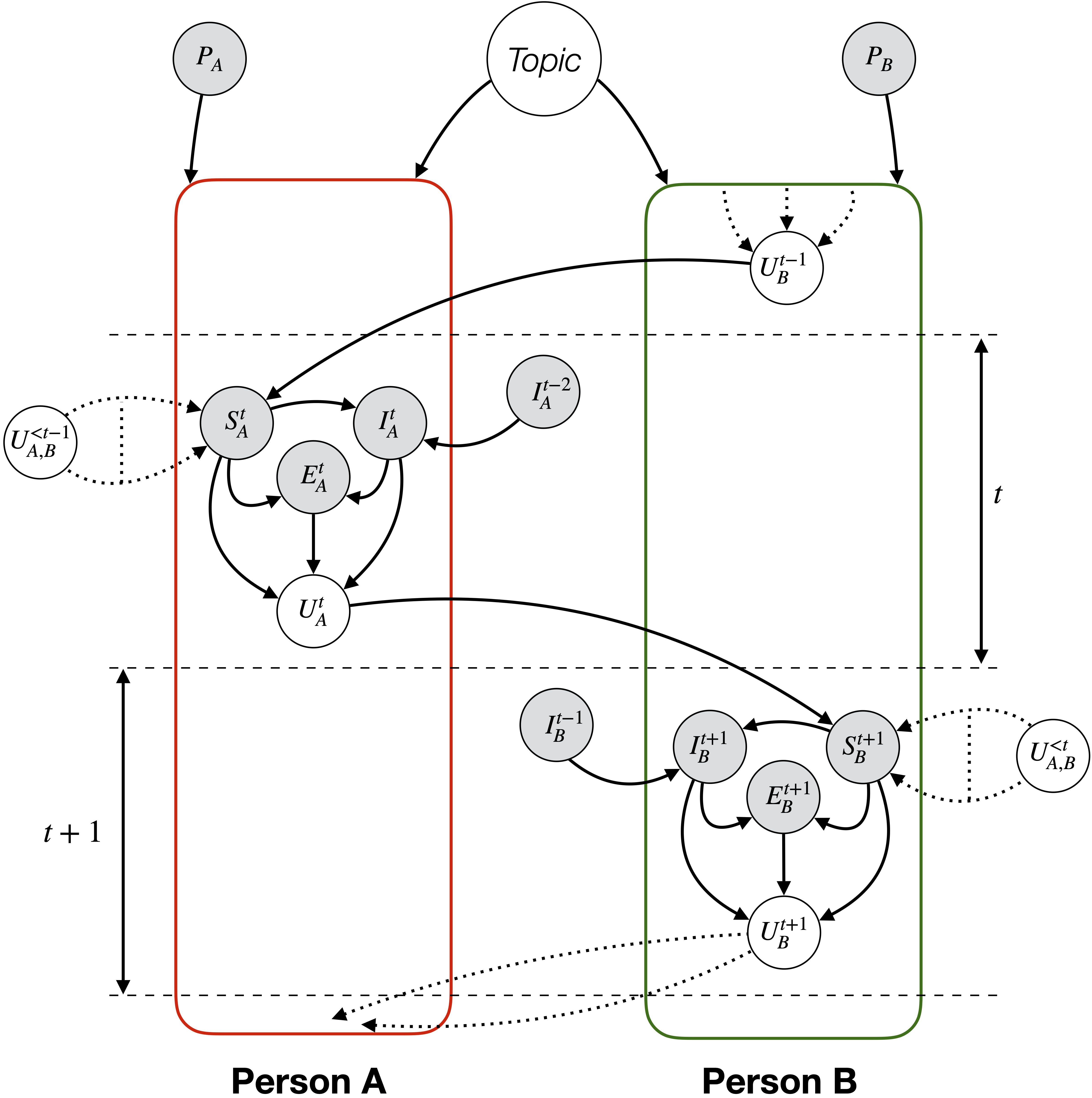
Conversations - task oriented and chit-chat - are governed by multiple pragmatic factors, such as topic, interlocutors’ personality, argumentation logic, viewpoint, and intent. As seen in the figure, topic (\(Topic\)) and interlocutor personality (\(P_*\)) influence the conversation throughout. For each utterance, the speaker makes up their mind (\(S^t_*\)) about the reply (\(U^t_*\)) based on the preceding utterances (\(U^{< t}_*\)) from both the interlocutors, the previous utterance being the most important one to make the largest change in the joint task model (for task-oriented conversations) or the speaker’s emotional state (for chit-chat). Delving deeper, the pragmatic features mentioned before, are encoded in speaker state (\(S^t_*\)). Intent (\(I^t_*\)) of the speaker is decided based on previous intent \(I_*^{t-2}\) and speaker state \(S_*^t\), as the interlocutor may change his/her intent based on the counterpart’s utterance and current situation. Then, the speaker formulates appropriate emotion \(E_*^t\) for the response based on the state \(S^t_*\) and intent \(I^t_*\). Finally, the response \(U^t_*\) is produced based on the speaker state \(S^t_*\), intent \(I^t_*\), and emotion \(E^t_*\). We surmise that considering these factors would help representing the argument and discourse structure of the conversation, which leads to improved dialogue understanding, including emotion recognition and also dialogue generation.