

Lab Note · Paper Explainer
δ-mem: Giving Large Language Models Lightweight, Online, and Dynamically Evolving Memory
Large language models are moving from single-turn question answering toward long-term assistants and complex task-oriented agents. They are expected to understand users over sustained interactions, track ongoing tasks, accumulate experience, and reuse historical information in future reasoning.
Why Memory Is Not Just Longer Context
This paper starts from a simple but important question: how can a model truly possess memory?
Here, memory does not simply mean expanding the context window. Putting more history into the prompt gives the model a chance to see the past, but it does not guarantee that the model can effectively use it. Memory should mean the ability to accumulate, update, compress, and retrieve historical information under the current context. A model should not only store the past; it should know when and how to use it for the current problem.
Traditional LLMs mainly rely on the current input context for reasoning. If all previous events are placed into the prompt, the model can in principle access that historical information. But this reduces the memory problem to a long-context problem. Standard Transformer attention becomes costly as the context grows, and longer context does not necessarily imply better utilization. In practice, models can suffer from dispersed attention, forgotten key information, and long-context degradation.
Long-term agents need a more efficient memory mechanism. Such a mechanism should not endlessly increase the context burden like full-text retrieval, and it should not behave like static parametric memory that becomes fixed after training. It should update dynamically during interaction and directly influence the model’s internal computation during inference.
The Core Idea
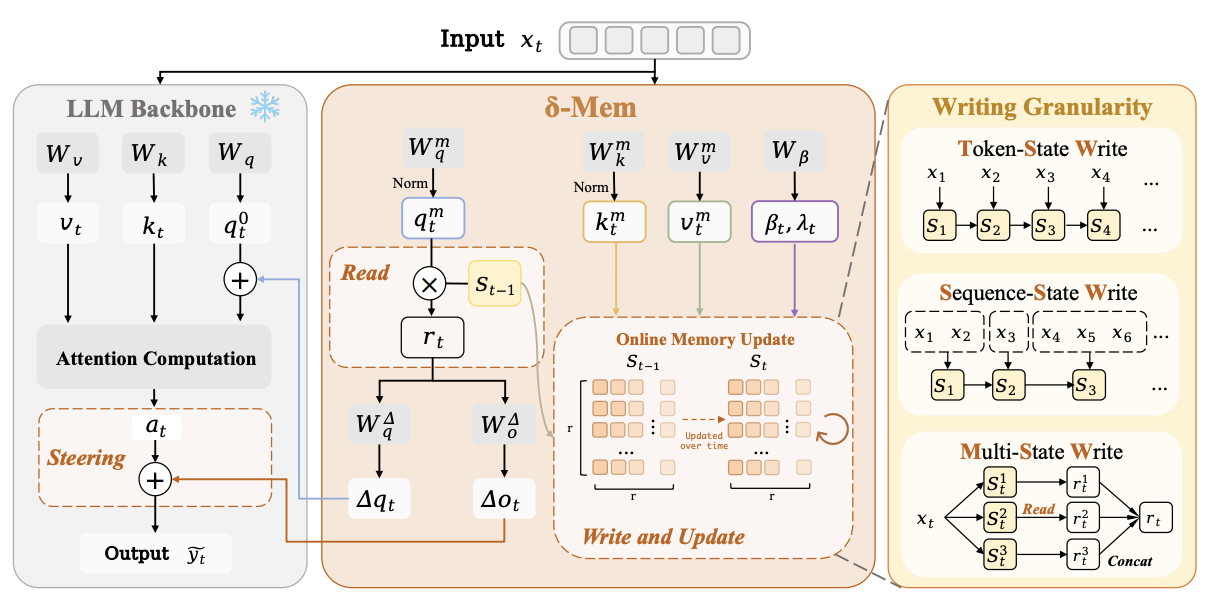
The core idea of δ-mem is straightforward: instead of rewriting all historical information back into the textual context, it compresses history into a compact online state and lets that state directly participate in Transformer attention computation.
δ-mem introduces an Online State of Associative Memory alongside a frozen full-attention backbone. When a new token or interaction segment arrives, the model projects the current information into a low-dimensional memory space and writes it into the state through delta-rule learning. This write is not simple accumulation. It performs residual writing based on the prediction error of the current state.
This gives δ-mem two important properties. First, it is online: the model can continuously update its memory state as new inputs arrive without retraining the entire backbone. Second, it is compact: in the main setting, δ-mem uses only an 8 x 8 online state matrix, yet it improves multiple memory-heavy benchmarks.
More importantly, δ-mem does not merely store historical information. During generation, the current input reads a context-dependent memory signal from the previous memory state. This signal is mapped into low-rank corrections and added to the attention computation of the frozen backbone. In the main implementation, δ-mem primarily modifies the query side and the output side. The query-side correction changes how the model retrieves and attends to information in the current context, while the output-side correction modulates the representation after attention.
In this way, historical memory is not appended to the prompt as extra text tokens. It enters the model’s internal computation through low-rank dynamic modulation.
How It Differs From Other Memory Mechanisms
Compared with textual memory mechanisms such as RAG, MemoryBank, or prompt compression, δ-mem does not convert memory back into natural language and insert it into the context. This avoids some information loss from textual compression while reducing retrieval noise and context-window pressure.
Compared with outside-channel memory mechanisms, δ-mem does not depend on an independent retrieval module or a separate reader and fusion pathway. The memory state directly produces low-rank attention corrections, which couples memory more tightly to the backbone’s attention computation.
Compared with parametric memory mechanisms such as LoRA, Prefix-Tuning, or model editing, δ-mem is not a static parameter update. LoRA-style low-rank parameters are usually fixed after training. δ-mem also uses a low-rank interface, but its corrections are driven by a dynamically evolving online memory state. The same parameters can therefore produce different steering effects under different historical states, making the mechanism more suitable for evolving user preferences, task progress, dialogue history, and agent trajectories.
Three Ways To Write Memory
The paper studies three write granularities.
- Token-State Write (TSW): the state is updated at every token. This captures fine-grained information changes, but it can be sensitive to formatting symbols, repeated expressions, and local noise.
- Sequence-State Write (SSW): the hidden states of a message or segment are averaged and written once per segment. This reduces redundant writes and makes state evolution smoother.
- Multi-State Write (MSW): multiple parallel memory states are maintained, allowing different states to carry different information types and reducing overwriting within a single state.
What The Experiments Show
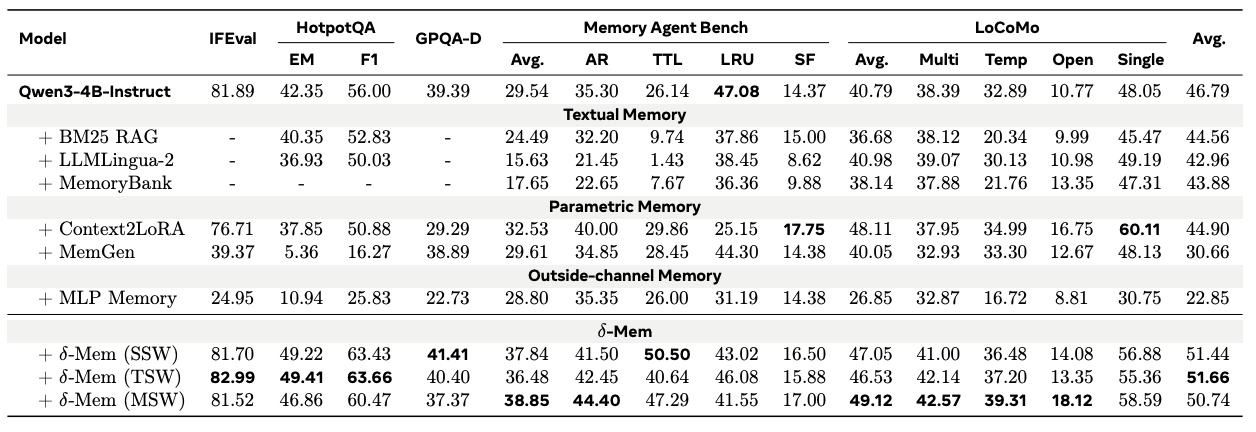
Experimental results show that δ-mem delivers consistent gains across memory-heavy and general capability benchmarks. On the Qwen3-4B-Instruct backbone, the TSW version improves the overall average score from 46.79% to 51.66%, a gain of 4.87 percentage points over the frozen backbone. Compared with Context2LoRA, the strongest non-δ-mem memory baseline in the reported results, δ-mem improves performance by 6.76 percentage points.
The gains are especially visible on memory-intensive evaluations. On MemoryAgentBench, δ-mem increases the average score from 29.54% to a maximum of 38.85%. On LoCoMo, MSW reaches the highest score of 49.12%. On HotpotQA, TSW improves EM/F1 from 42.35% / 56.00% to 49.41% / 63.66%.
These results suggest that the improvement does not simply come from adding more parameters. It comes from a memory organization mechanism better suited to long-term interaction: compressing history into a fixed-size online state and letting that state influence reasoning through attention corrections.
Does The State Really Store Useful History?
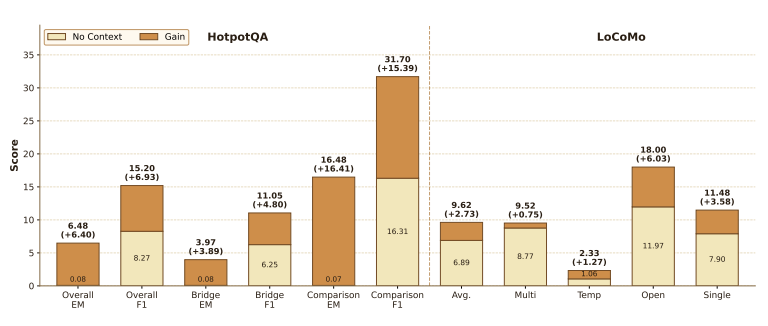
The paper also introduces a no-context recovery experiment. In this setting, the original historical context is removed, and the model can rely only on the compressed memory state to answer questions.
The results show that δ-mem still significantly outperforms the no-context baseline on HotpotQA and LoCoMo. For example, on HotpotQA, overall EM improves from 0.08% to 6.48%, and overall F1 improves from 8.27% to 15.20%. This indicates that even when the explicit context is no longer available, the online state can still recover part of the task-relevant historical signal.
Why It Is Lightweight
From an efficiency perspective, δ-mem is deliberately small. In the main experiments, SSW and TSW introduce only 4.87M trainable parameters, about 0.12% of the Qwen3-4B backbone. The multi-state MSW version uses 19.47M parameters, about 0.48%.
Inference efficiency experiments further show that δ-mem memory usage is close to the base model, suggesting that the small recurrent state introduces little memory burden. Decoding can be slightly slower because the state must be updated, but the mechanism remains substantially lighter than heavier memory modules.
Why This Matters
δ-mem offers a different design paradigm for LLM memory. Memory does not have to be text, an external database, or a static parameter update. It can be a small online state that evolves dynamically with interaction and directly modulates Transformer attention through a low-rank interface.
This design is especially relevant for long-term assistants and agent systems. Assistants need to remember user preferences, task backgrounds, and interaction history. Agents need to track progress, environmental feedback, and previous decisions. Complex QA systems need to reuse past evidence when answering current questions.
The core contribution of δ-mem is therefore not merely a new adapter. It rethinks the interface for LLM memory: how memory should be stored, how it should be updated, and how it should enter the reasoning process.
By directly coupling a compact online state with attention computation, δ-mem points toward LLMs with more efficient, dynamic, and long-term-interaction-oriented memory capabilities while keeping the backbone frozen.