Abstract
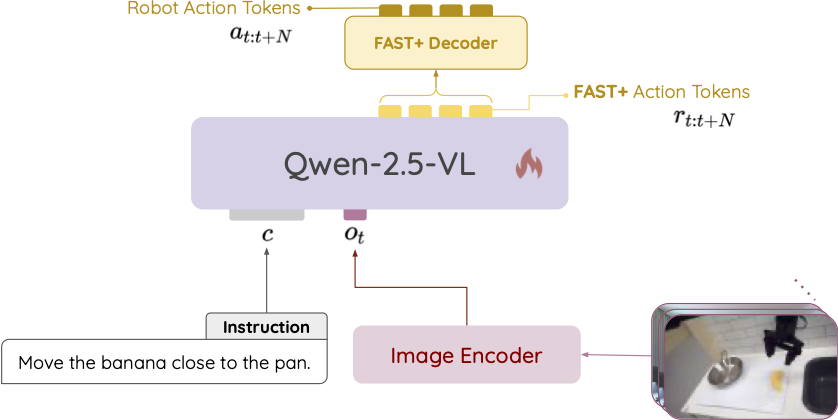
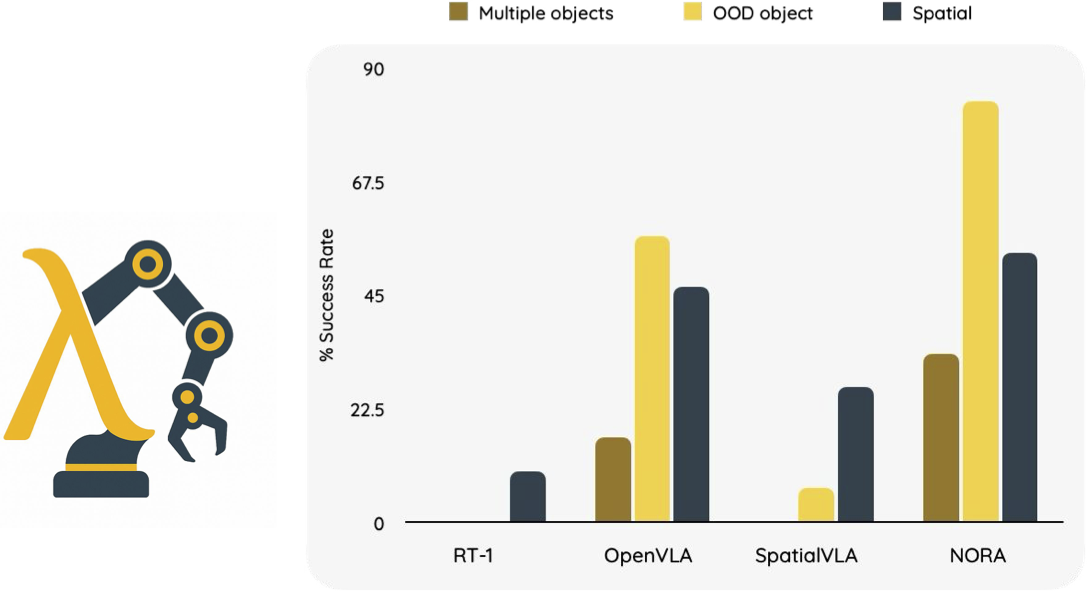
Existing Visual-Language-Action (VLA) models have shown promising performance in zero-shot scenarios, demonstrating impressive task execution and reasoning capabilities. However, a significant challenge arises from the limitations of visual encoding, which can result in failures during tasks such as object grasping. Moreover, these models typically suffer from high computational overhead due to their large sizes, often exceeding 7B parameters. While these models excel in reasoning and task planning, the substantial computational overhead they incur makes them impractical for real-time robotic environments, where speed and efficiency are paramount. Given the common practice of fine-tuning VLA models for specific tasks, there is a clear need for a smaller, more efficient model that can be fine-tuned on consumer-grade GPUs. To address the limitations of existing VLA models, we propose NORA, a 3B-parameter model designed to reduce computational overhead while maintaining strong task performance. NORA adopts the Qwen-2.5-VL-3B multimodal model as the backbone, leveraging its superior visual-semantic understanding to enhance visual reasoning and action grounding. Additionally, our NORA is trained on 970k real-world robot demonstrations and equipped with the FAST+ tokenizer for efficient action sequence generation. Experimental results demonstrate that NORA outperforms existing large-scale VLA models, achieving better task performance with significantly reduced computational overhead, making it a more practical solution for real-time robotic autonomy.
The Framework