Contextualized Commonsense Inference in Dialogues (CICERO)
The purpose of this repository is to introduce new dialogue-level commonsense inference datasets and tasks. We chose dialogues as the data source because dialogues are known to be complex and rich in commonsense. At present, we have released two versions of the dataset:
CICERO-v1
CICERO : A Dataset for Contextualized Commonsense Inference in Dialogues (ACL 2022)
CICERO-v2
Multiview Contextual Commonsense Inference: A New Dataset and Task
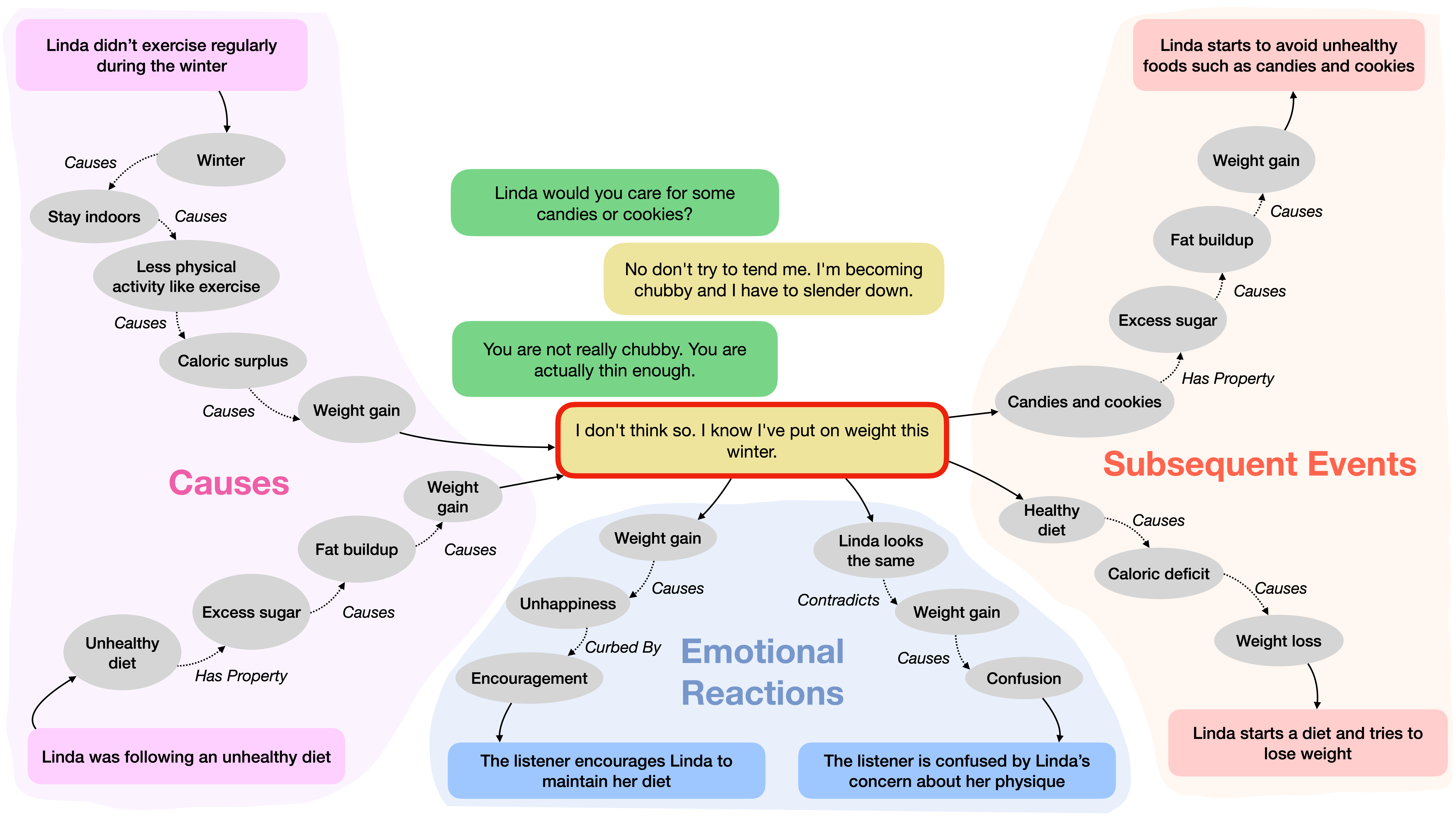
Depending on a situation, multiple different reasonings are possible each leading to various unique inferences. In constructing CICERO-v2, we asked annotators to write more than one plausible inference for each dialogue context. We call this task — Multiview Contextual Commonsense Inference, a highly challenging task for large language models. CICERO-v2 contains more than 8000 dialogue contexts each manually annotated with more than one plausible inferences for the following relation types: cause, subsequent event, emotional reaction, motivation.
Citation
If these datasets are useful in your research, cite the following papers:
Multiview Contextual Commonsense Inference: A New Dataset and Task. Siqi Shen and Deepanway Ghosal and Navonil Majumder and Henry Lim and Rada Mihalcea and Soujanya Poria. Arxiv 2022.