Figure illustrates the our hierarchical planning framework
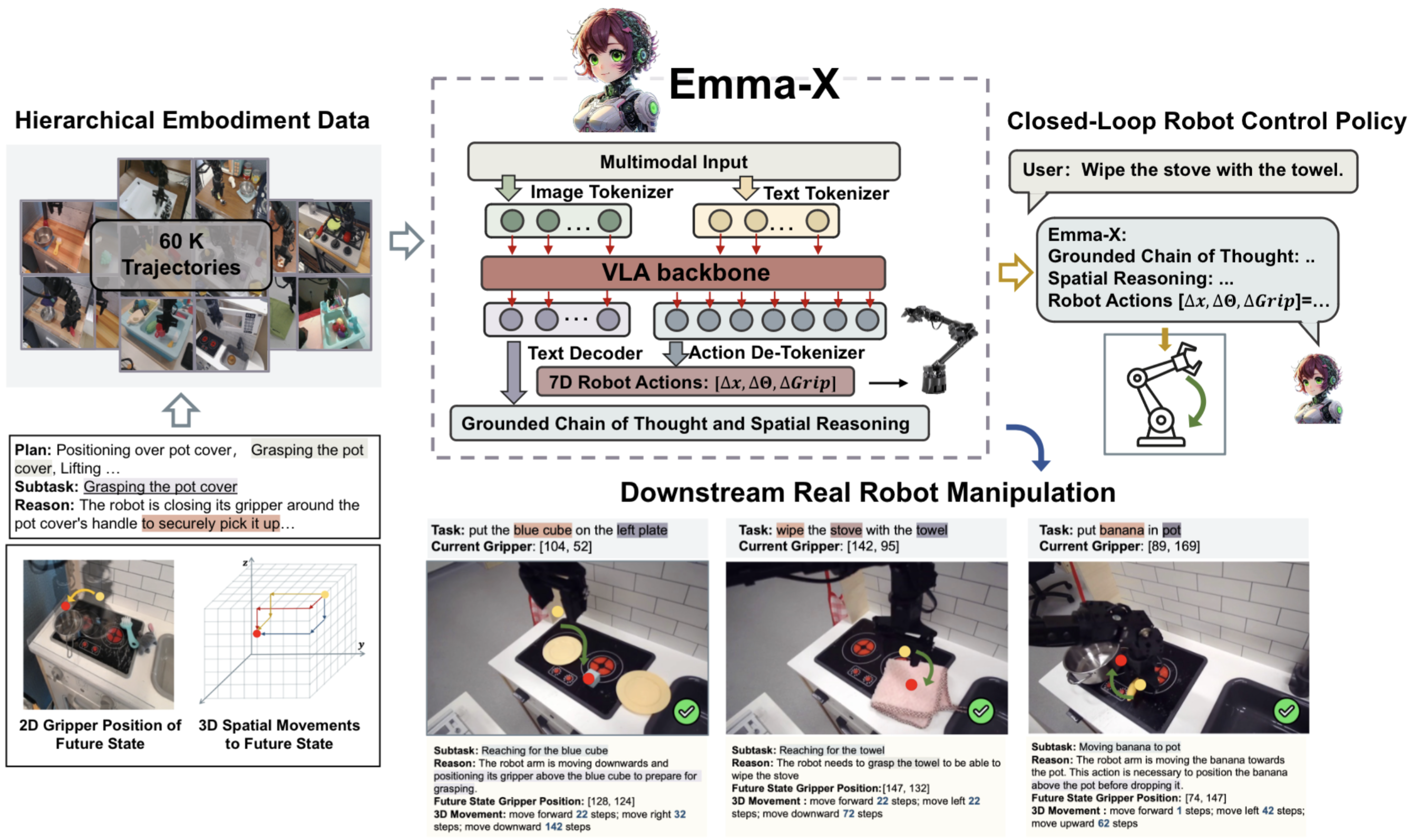
We introduce Emma-X, a 7B-parameter embodied multimodal action model created by fine-tuning OpenVLA with grounded chain-of-thought (CoT) reasoning data. To support this, we synthetically construct a hierarchical embodiment dataset from existing robot manipulation datasets, incorporating 3D spatial movements, 2D gripper positions, and grounded reasoning. Additionally, we propose a novel trajectory segmentation strategy that utilizes the gripper’s opening and closing states alongside the robot arm’s motion trajectory, enabling grounded task reasoning and look-ahead spatial reasoning.
Our GCoT policy is built atop OpenVLA, which fine-tunes a Prismatic VLMs to take in images and instructions to output actions.
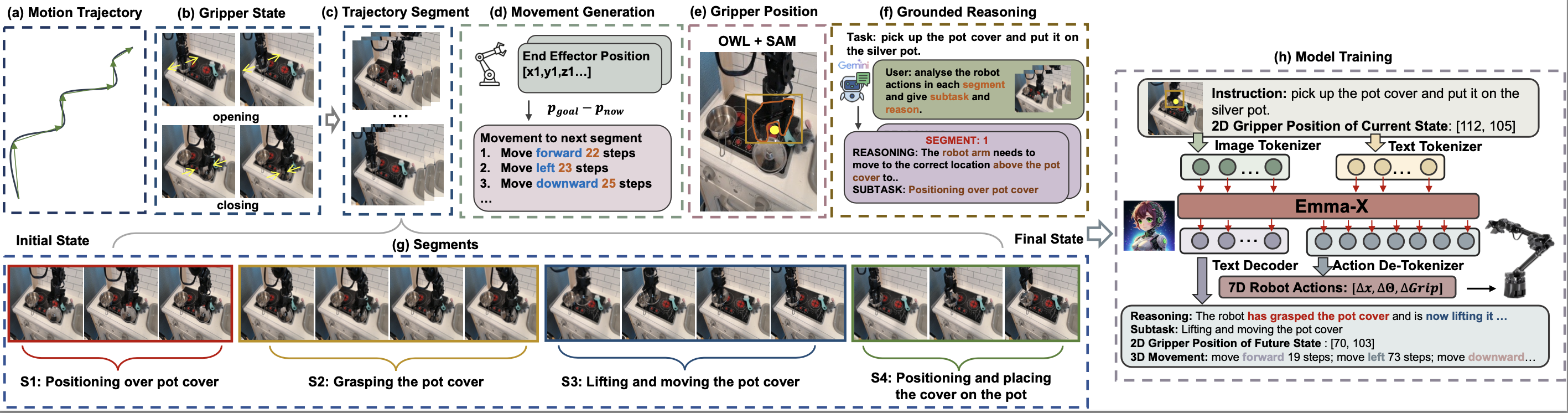
Figure illustrates the construction of our Hierarchical Embodied dataset
We develop a hierarchical embodiment dataset based on BridgeV2, consisting of 60,000 robot manipulation trajectories. For each state of a given trajectory, we generate detailed spatial reasoning grounded in the environment and task reasoning, such as the plans of how the robot should perform the subtask. We also generate the 2D gripper position, and 3D spatial movements of the gripper to transit to future states, which enable the VLA model to reason a long-horizon plan for accomplishing the task. Furthermore, we utilize Gemini to generate grounded task reasoning for each observed state. To avoid the abovementioned reasoning conflict problem of task reasoning in ECoT, we propose a novel trajectory segmentation strategy, which leverages the opening and closing states of the gripper and the motion trajectory of the robot arm to segment the sequence of states into distinct segments.
We construct a suite of 12 evaluation tasks to test how well Emma-X deals with novel objects, instructions, and spatial relations. We compare our policy against several baselines: OpenVLA, and ECOT.
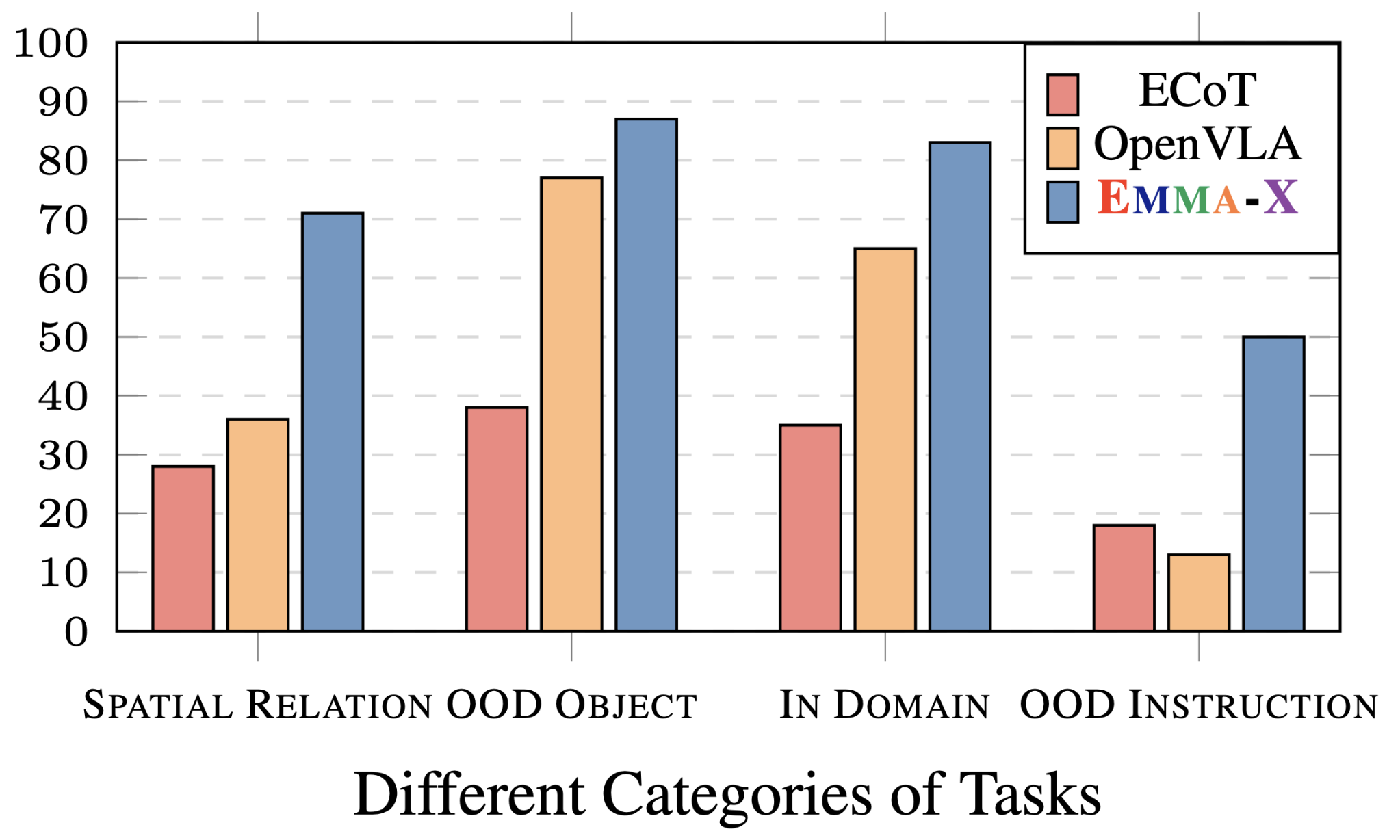
Evaluation success rates of our ECoT policy compared against several popular generalist robot policies.
After running over 120 real-world evaluation trials per policy, we find that Emma-X achieves significant performance improvements over competitive baselines in various real-world robot tasks, particularly those requiring spatial reasoning, and OOD tasks
It achieves comparable performance to OpenVLA on both in-domain and out-of-domain object tasks.
@article{sun2024emma,
title={Emma-X: An Embodied Multimodal Action Model with Grounded Chain of Thought and Look-ahead Spatial Reasoning},
author={Sun, Qi and Hong, Pengfei and Pala, Tej Deep and Toh, Vernon and Tan, U and Ghosal, Deepanway and Poria, Soujanya and others},
journal={arXiv preprint arXiv:2412.11974},
year={2024}
}